This is not my first language as I done some proprietary scripting and experimental parsers in the past. This did not lead anywhere expect to influence how I want Plain Assembler to be designed.
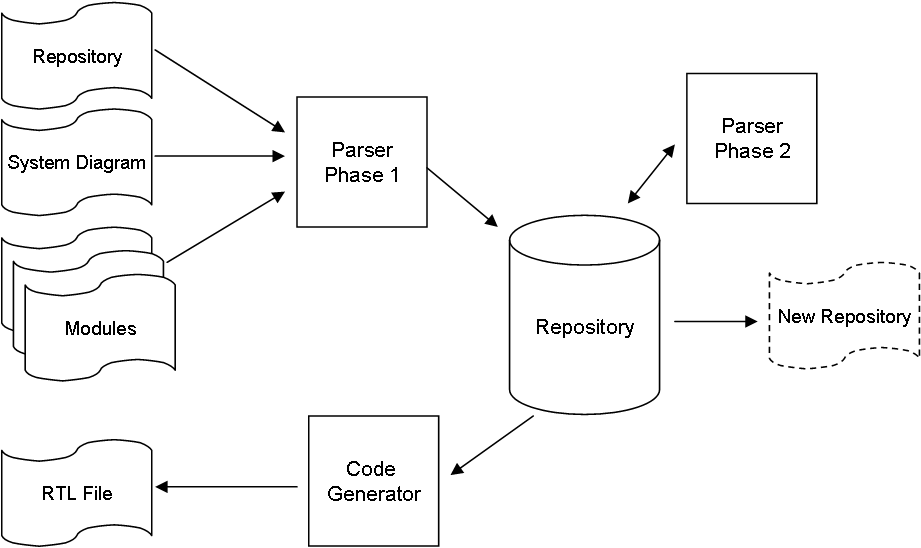
The drawing above illustrate the main components.
Repository is a fancy word for a database. Plain is unique as it start by demanding a database in XML format to describe our platform. This file get read into the internal repository before parsing starts. As we parse we build the complete repository that also can be saved back out in XML format and used for the next assembly process so that we don’t have to re-parse everything. Using XML rather than a binary format makes sense because it enable me a way to inspect content + parsing xml is actually far faster than reading a binary file – I know this will surprise some.
The parser read the system diagram and module(s). Each module generate a RTL file that is used to download the plain module(s) one by one. Parsing needs to be 2-pass. We first parse the file and secondly solve “forward assumptions”.
The code generator uses the repository to generate a RTL (Real Time Linker) file. The RTL file is sent to the VM that will link together the final binary module that we execute.
All in all it is a bit of work, but it is not that complicated once you get started. The key is that we need to be systematic as we will have parsing and code generator for each statement – which is why I want to use C++ because we take advantage of object orientation and let each statement be a C++ class that sustain parsing, repository management, code generation and in general everything for that statement. Using C++ this way also give me a single file for “if” etc making it easy to track and maintain. It creates more code, but it makes a lot of sence as the code get readable and easy to maintain.